

ChatGPTを社内導入するとき、承認会議で止まりやすいのは「AIを使ってよいか」よりも、「使った後に説明できる状態になっているか」です。誰が、いつ、どの業務で、何を入力し、どの出力を使い、どの資料を参照したのか。ここが曖昧なままPoCを始めると、誤回答、個人情報入力、退職者アカウント、権限過多、監査依頼に対応できないといった問題が後から表面化します。
この記事では、ChatGPT Enterprise、ChatGPT Business、OpenAI API Platformを社内利用する前提で、情シス・情報セキュリティ・法務・現場部門が合意すべき監査ログ設計を整理します。ポイントは、ベンダーが持つログと、自社が説明責任のために持つログを分けて考えることです。
https://openai.com/enterprise-privacy/
https://help.openai.com/en/articles/9261474-openai-compliance-platform-for-enterprise-and-edu-customers
https://help.openai.com/en/articles/9687866-admin-and-audit-logs-api-for-the-api-platform
最初に結論:監査ログは「会話の全文保存」から考えない
監査ログ設計で最初に決めるべきことは、「会話を全部保存するか」ではありません。最初に決めるべきなのは、次の4点です。
- 監査で説明したい問いは何か
- その問いに答えるために必要な最小項目は何か
- どの情報はベンダー側、どの情報は自社側で持つのか
- 保持期間・閲覧権限・削除手順を誰が承認するのか
たとえば問い合わせ対応であれば、監査時に問われるのは「AIが何を答えたか」だけではありません。「どの顧客チケットで使ったのか」「参照したFAQはどれか」「担当者が最終確認したのか」「個人情報を入力していないか」まで確認できる必要があります。逆に、全プロンプト原文を無制限に保存すると、個人情報や機密情報をログ側に複製するリスクが増えます。
したがって、基本方針は次のように置くと現場で運用しやすくなります。
監査ログは、AI利用の再現ではなく、AI利用の説明責任を果たすために残す。原文保存は例外扱いとし、通常は入力要約、出力、参照ID、業務ID、操作者、時刻、承認状態を最小セットにする。
ChatGPTのプラン・用途別に、公式情報で確認できること
ChatGPTまわりのログ仕様は、ChatGPT Enterprise/Edu向けのCompliance Platform、ChatGPT Businessの管理者機能、API PlatformのAudit Logs APIで性質が異なります。記事や稟議書に書くときは、この違いを混ぜないことが重要です。
| 対象 | 公式情報で確認できる内容 | 設計上の注意 |
|---|---|---|
| ChatGPT Enterprise/Edu | ワークスペース管理者は、Enterprise Compliance APIを通じて会話やGPTsの監査ログにアクセスできると説明されている。 | 実際に取得できる項目、連携方式、利用可能範囲は契約・管理画面・テナント設定で確認する。 |
| Compliance Logs Platform | ChatGPTワークスペースのログとメタデータをeDiscovery、DLP、SIEMツールに接続できる。Compliance Logs Platformのデータ保持は30日間で、より長期に保持したい場合は継続的にダウンロードして自社ポリシーに従って保存する必要がある。 | 「OpenAI側で長期保存される」と誤解しない。自社保持が必要なら、取り込みバッチ、保管先、失敗時の再取得手順を設計する。 |
| ChatGPT Business | ワークスペース管理者は、ワークスペース内のエンドユーザー会話を表示、アクセス、エクスポート、削除できると説明されている。ワークスペースデータの保持期間は管理者が制御する。 | 管理者がどこまで閲覧するかは、プライバシー・就業規則・社内規程と合わせて決める。 |
| OpenAI API Platform | Audit Logs APIでは、APIキー、招待、ユーザー・サービスアカウント、ログイン/ログアウト失敗、組織設定、プロジェクトのライフサイクルなどを追跡できる。API Platformの監査ログには固定の保持期間やTTLはなく、永続的な利用可能性は保証されないと説明されている。 | API利用ログとChatGPTワークスペースの会話ログを混同しない。必要な監査ログは自社SIEMやログ基盤へ取り込む。 |
https://openai.com/enterprise-privacy/
https://help.openai.com/en/articles/9261474-openai-compliance-platform-for-enterprise-and-edu-customers
https://help.openai.com/en/articles/9687866-admin-and-audit-logs-api-for-the-api-platform
監査ログ設計で決めるべき7項目
監査ログ設計は、次の7項目に分けると承認会議で議論しやすくなります。特に保持期間は、公式サービス仕様だけでは決まりません。自社の契約、規程、法務判断、対象業務のリスクによって変わるため、初期案と確定時に確認する内容を分けて整理します。
| 項目 | 決める内容 | 初期案 | 確定時に確認すること |
|---|---|---|---|
| 対象業務 | どの業務でChatGPTを使うか | 問い合わせ対応、社内FAQ、議事録要約、帳票確認などに分類する | 利用申請、業務一覧、部門ヒアリングをもとに対象業務を整理する |
| 入力ログ | プロンプト原文を保存するか、要約にするか | 原則は入力要約。原文保存は法務・情報セキュリティ承認がある場合のみ | 個人情報、機密情報、顧客情報、認証情報が入力される可能性を確認する |
| 出力ログ | AI出力をどの粒度で残すか | 業務判断に使った出力は全文、試行錯誤の途中出力は要約または保存対象外 | 顧客提示、社外提出、承認判断、帳票作成に使った出力を保存対象として定義する |
| 参照情報 | AIが参照したファイルや社内資料をどう紐付けるか | ファイルID、版数、ハッシュ、格納場所、チケットIDを残す | 社内文書管理システム、チケット管理、ファイル共有サービスのID体系と紐付ける |
| 操作者・時刻 | 誰がいつ利用したか | ユーザーID、部署、ロール、タイムスタンプ、利用アプリを残す | SSO、ID管理、退職者・異動者の停止手順と照合できる項目を残す |
| 保持期間 | ログをどれだけ保存するか | 公式サービス側の保持仕様とは別に、自社保存期間を定義する | 問い合わせ対応、監査対応、契約上の保存義務、法定保存、削除基準をもとに決める |
| 閲覧権限 | 誰がログを見られるか | 情シス、情報セキュリティ、監査担当、法務などに限定し、閲覧ログも残す | ログ閲覧者、承認者、エクスポート権限、閲覧履歴の保存方法を決める |
個人情報を含むプロンプトはどう扱うか
個人情報保護委員会は、生成AIサービスの利用に関する注意喚起を公表しています。社内でChatGPTを使う場合、個人情報を含むプロンプト入力は「便利だから入力する」ではなく、利用目的、必要性、入力範囲、サービス側の取扱いを確認したうえで判断する必要があります。
実務では、次のようにルール化すると現場に伝わりやすくなります。
- 顧客名、メールアドレス、電話番号、住所、契約番号などは原則入力しない。
- 問い合わせ文を使う場合は、個人を識別できる情報をマスクしてから入力する。
- 要配慮個人情報に該当し得る情報は、PoC段階では入力禁止にする。
- ログにはプロンプト原文ではなく、マスク後の入力要約を残す。
- 例外入力が必要な業務は、事前に法務・個人情報保護担当・情報セキュリティの承認を必須にする。
https://www.ppc.go.jp/news/careful_information/230602_AI_utilize_alert/
業務別:最小ログ項目テンプレート
すべての業務で同じログを残そうとすると、現場の負荷が高くなります。業務ごとに「最低限これがあれば後から説明できる」という項目に絞り、PoCで足りない項目を追加する流れにします。
1. 問い合わせ対応でChatGPTを使う場合
| ログ項目 | 残す内容 | 理由 |
|---|---|---|
| 業務ID | チケットID、顧客区分、問い合わせ分類 | どの問い合わせでAIを使ったか追跡するため |
| 入力 | マスク後の入力要約、テンプレートID | 個人情報をログに複製せず、利用目的を説明するため |
| 出力 | 顧客回答に利用したAI出力、または採用した要約 | 誤案内発生時に原因を確認するため |
| 参照情報 | FAQ ID、ナレッジ記事ID、版数、ファイルハッシュ | 古い資料を参照していないか確認するため |
| 人による確認 | 確認者ID、確認時刻、修正有無 | AI出力をそのまま送ったのか、人が確認したのかを区別するため |
2. 社内文書・議事録要約で使う場合
議事録や社内文書は、機密情報が含まれやすい領域です。会話全文よりも、対象ファイル、版数、要約結果、共有範囲、削除予定日を残すほうが実務的です。
【議事録要約ログのひな型】
利用日時:YYYY-MM-DD HH:MM
利用者:部署/ユーザーID
対象会議:会議IDまたは案件ID
入力情報:議事録ファイルID、版数、マスク有無
AI出力:要約結果ファイルID
共有先:部署名またはグループID
削除予定:会議体の保存ルール、案件の完了時期、監査・確認に必要な期間をもとに削除予定日を記載し、共有範囲も定期的に見直す
確認者:承認者ID、確認時刻
3. 帳票・PDF確認で使う場合
帳票確認では、AIの出力だけでなく、対象ファイルの同一性を示す情報が重要です。ファイル名だけでは差し替えに弱いため、ファイルID、版数、ハッシュ、格納パスを残します。
- 帳票番号
- 対象ファイルID
- ファイルハッシュ
- AIに依頼した確認内容の要約
- AI出力の要約または差分指摘
- 最終確認者
- 修正後ファイルID
ベンダーログだけに頼らない理由
自社でログをSQL Serverに収集している立場として、設計時に必ず詰めるのは「紐付け」と「保持期間とコスト」です。ベンダー提供のログだけだと、顧客ID、チケットID、ファイルIDといった結合キーが足りず、いざ調査というときに一件をトレースできないことがあります。そのため、チケットIDやハッシュで一発で引ける形で持ち、全文は短期、要約は長期というように保持期間を分けて、ストレージコストを抑えています。
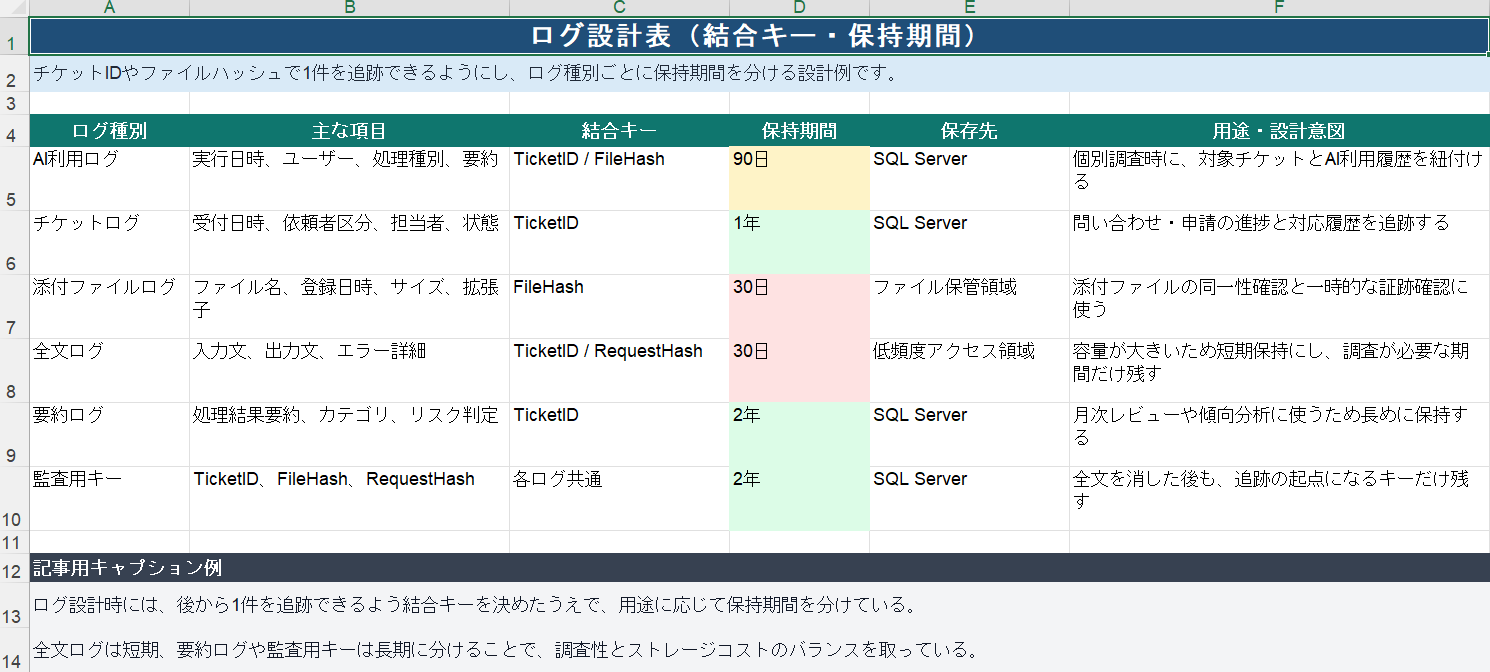
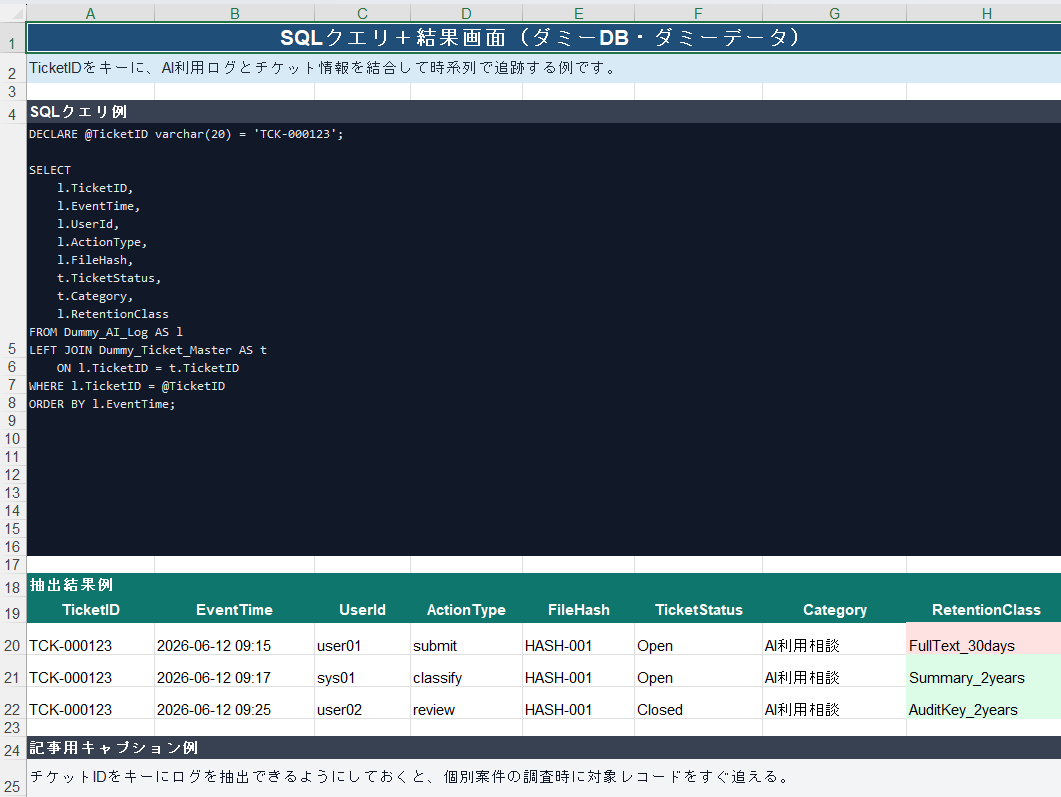
OpenAIの公式情報では、Enterprise/EduのCompliance Platform、Businessの管理者機能、API PlatformのAudit Logs APIなどが説明されています。ただし、これらは自社の業務ID、顧客チケットID、社内文書ID、承認者、社内規程上の保存区分まで自動で埋めてくれるものではありません。
そのため、監査ログ設計では次の分担にします。
| 領域 | ベンダー側で確認するもの | 自社側で設計するもの |
|---|---|---|
| 利用者・権限 | 管理者、ユーザー、認証、監査ログ取得可否 | 部署、職務、承認者、退職・異動時の棚卸し |
| 会話・出力 | 会話やメタデータの取得可否、エクスポート可否 | 業務ID、採用した出力、顧客回答との紐付け |
| 保持期間 | サービス側の保持仕様、削除仕様 | 自社ログ保存期間、削除承認、監査証跡 |
| 監査提示 | 取得できるログ形式、API、連携先 | 監査時の提示フォーマット、責任者、提出期限 |
PoC開始前チェックリスト
PoCを始める前に、次の項目が未決なら開始しない、という基準を置くと差し戻しを減らせます。
- 対象業務と利用者が決まっている
- 入力禁止情報が明文化されている
- プロンプト原文を保存するか、要約のみ保存するかが決まっている
- AI出力を業務判断に使う条件が決まっている
- ログ保存先が決まっている
- ログ閲覧者と承認者が決まっている
- 監査ログの保存期間について、PoC中の暫定保存期間と本番移行前に確定する保存期間の決め方が整理されている
- 退職者・異動者のアクセス削除手順が決まっている
- インシデント時の連絡先が決まっている
PoC中に検証すること:7日間で見るべき観点
PoCでは「便利だったか」だけでなく、ログが後から追えるかを検証します。期間は自社事情に応じますが、初回検証では最低でも1件の業務を最初から最後までトレースしてください。
| タイミング | 検証項目 | 合格条件 |
|---|---|---|
| 開始前 | ログ項目、保存先、閲覧権限、責任者の確認 | 承認会議の議事録に残っている |
| 初回利用 | 入力要約、出力、参照ID、操作者、時刻が記録されるか | 1件の利用をチケットIDまたは業務IDで追える |
| 中間確認 | 個人情報・機密情報がログに残りすぎていないか | マスク漏れがない、または是正手順がある |
| 終了前 | 監査提示フォーマットで出力できるか | 監査担当が読める形で提出できる |
| 本番移行判断 | 保存期間、コスト、権限、削除手順 | 未決項目が[要確認]として残っていない |
監査提示フォーマットのひな型
監査対応では、ログが存在するだけでは不十分です。監査担当や法務が読める形に変換できる必要があります。次のひな型を、チケット単位・案件単位で出せるようにしておきます。
【ChatGPT利用監査 提示フォーマット】
監査対象期間:YYYY-MM-DD 〜 YYYY-MM-DD
対象業務:問い合わせ対応/社内文書要約/帳票確認 など
業務ID:チケットIDまたは案件ID
利用者:部署、ユーザーID、ロール
利用日時:YYYY-MM-DD HH:MM
入力内容:マスク後の入力要約
出力内容:業務判断に利用したAI出力または出力ID
参照情報:ファイルID、版数、ハッシュ、格納場所
人による確認:確認者ID、確認時刻、修正有無
保存先:アクセス制限、更新履歴、削除制限を設定できるログ保管場所を記載
保存期限:監査対応、問い合わせ対応、契約上の保存義務、法定保存の要否をもとに設定した期限を記載
閲覧履歴:監査ログ閲覧者、閲覧日時、目的
保持期間の決め方:公式仕様と自社規程を分ける
保持期間は長いほど監査には強くなりますが、ログ自体が個人情報や機密情報を抱え、ストレージコストも効いてきます。実際に運用していると「全部・長期」は現実的ではないため、全文は短期で要約に落とし、長期で残すのは紐付けに必要な最小項目だけにしています。
保持期間は、もっとも誤解が起きやすい項目です。たとえば、Compliance Logs Platformのデータ保持が30日間と説明されていても、それは自社の監査ログ保存期間が30日でよいという意味ではありません。長期保持が必要な場合は、自社で継続的にダウンロードし、自社ポリシーに従って保存する必要があります。
また、API Platformの監査ログについては、固定の保持期間やTTLはなく、永久的な利用可能性は保証されないと説明されています。したがって、APIキー作成・削除、ユーザー権限変更、プロジェクト変更などを監査証跡として残したい場合は、自社のログ基盤やSIEMへ取り込む前提で設計します。
https://help.openai.com/en/articles/9261474-openai-compliance-platform-for-enterprise-and-edu-customers
https://help.openai.com/en/articles/9687866-admin-and-audit-logs-api-for-the-api-platform
AIガバナンスとのつなげ方
監査ログ設計は、単なる情シス作業ではありません。経済産業省のAI事業者ガイドラインは第1.2版が公表されており、AIの開発・提供・利用にあたって必要な取組を示す資料として位置付けられています。社内でChatGPTを使う場合も、ログ設計をAIガバナンスの一部として扱うと、承認会議で説明しやすくなります。
実務では、次の3つをセットで提出します。
- AI利用ルール:何を入力してよいか、禁止するか
- 監査ログ設計:何を残し、誰が見て、いつ削除するか
- 本番移行基準:PoCで何が確認できたら本番利用を認めるか
https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/20260331_report.html
まとめ:ChatGPT監査ログは「後で説明できる最小セット」から始める
ChatGPTの監査ログ設計では、会話全文を残すかどうかだけを議論しても前に進みません。必要なのは、業務ID、入力要約、出力、参照情報、操作者、時刻、確認者、保存先、保持期間を、現場が運用できる粒度で決めることです。
公式情報で確認できるサービス側の仕様と、自社で決めるべき規程・契約・運用条件を分けて整理すれば、承認会議での論点はかなり減らせます。まずは1業務だけ選び、1件の利用を最初から最後まで追跡できるかを確認してください。そこで追えない項目こそ、本番導入前に埋めるべき監査ログの不足項目です。


コメント